Traditional reaction optimization - trial-and-error or one-factor-at-a-time - is slow, resource-intensive, and leaves most of the experimental space unexplored. ReactWise replaces that with a fundamentally smarter approach: Bayesian Optimization (BO), which learns from every experiment to tell you exactly where to look next.
BO integrates directly into the Design-Make-Test-Analyze (DMTA) cycle. At its core is a probabilistic model - a Gaussian Process - that continuously updates as new data arrives. Critically, it doesn't just predict outcomes; it quantifies uncertainty. Every prediction comes with a confidence range (e.g., 78 ± 4% yield), and the algorithm uses this to automatically balance two competing priorities: exploring promising but untested regions, and exploiting conditions already known to perform well. The result is fewer wasted experiments and faster convergence on optimal conditions.
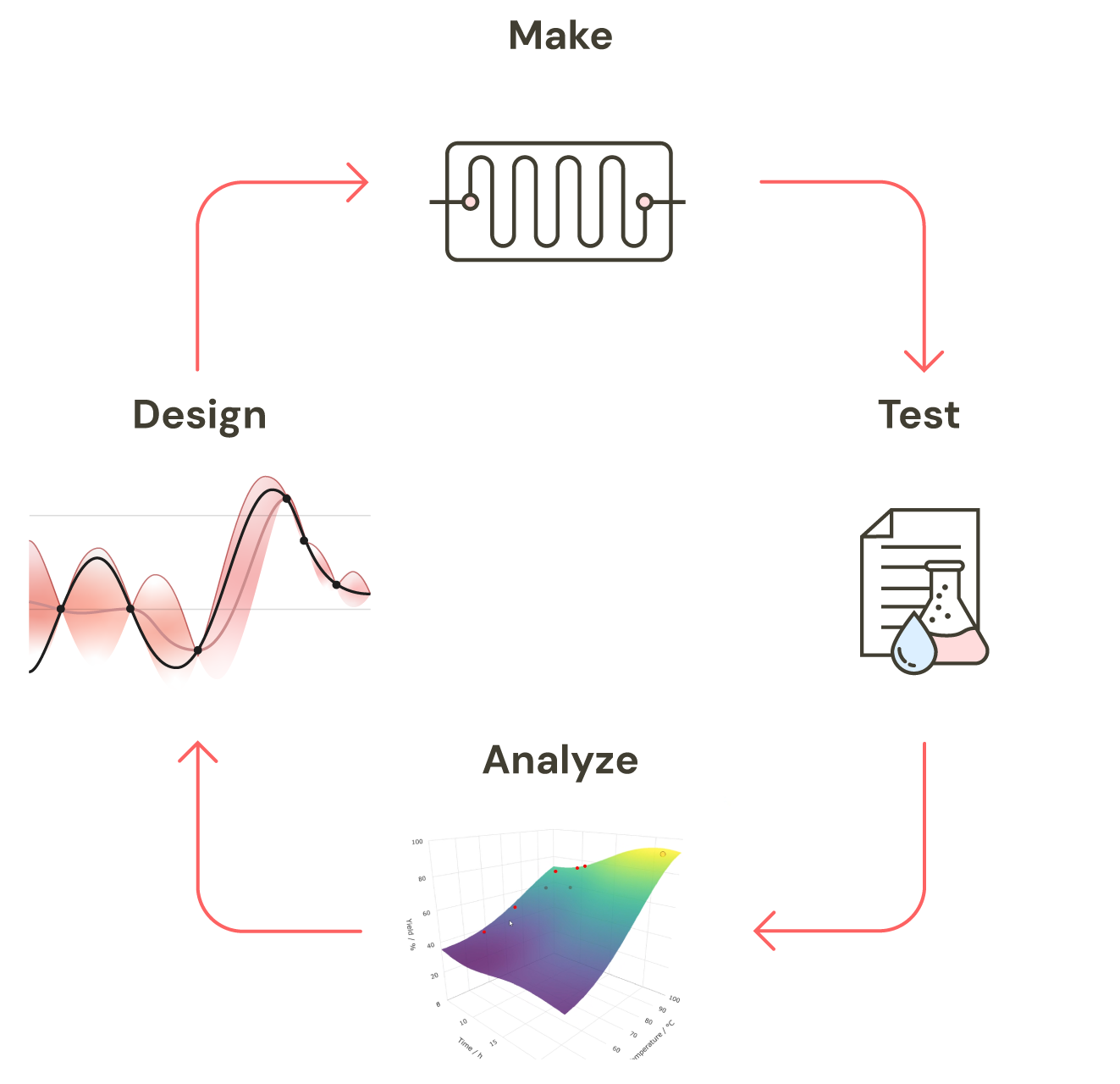

Standard BO is powerful - but it starts blind. Every new reaction begins from scratch, with no memory of what came before.
ReactWise’s MemoryBO® is built on Multi-Task Bayesian Optimization (MTBO), which changes this fundamentally. Rather than treating each reaction in isolation, MTBO jointly models related reactions - those sharing common reagents, mechanisms, or conditions - and learns which historical campaigns are most informative for the current target, and to what degree. Before a single new experiment is run, the model already arrives at an informed starting point.
This is the practical power of transfer learning applied to chemistry: the accumulated knowledge from past optimizations becomes an asset that compounds over time, not a silo that gets discarded. As new data comes in, the model updates across all related tasks simultaneously - meaning insights flow in both directions. A new reaction sharpens understanding of its neighbors, and vice versa.
The outcome
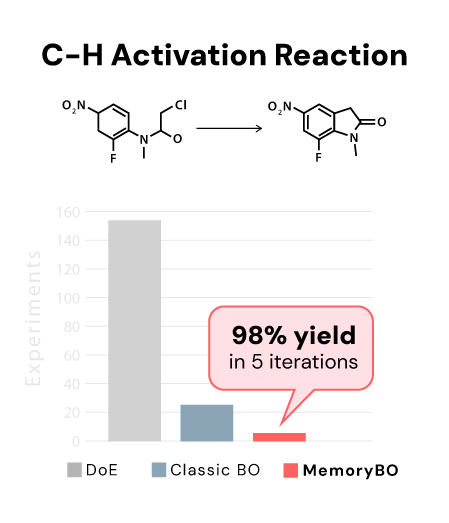
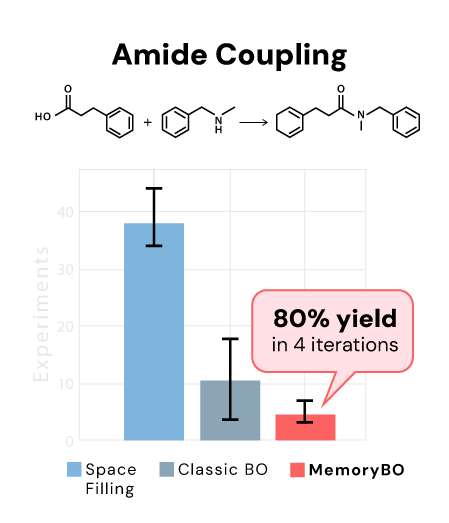
MTBO reaches optimal conditions significantly faster than single-task approaches, with the advantage most pronounced exactly when it matters most - early in optimization, when data is scarce and every experiment counts.


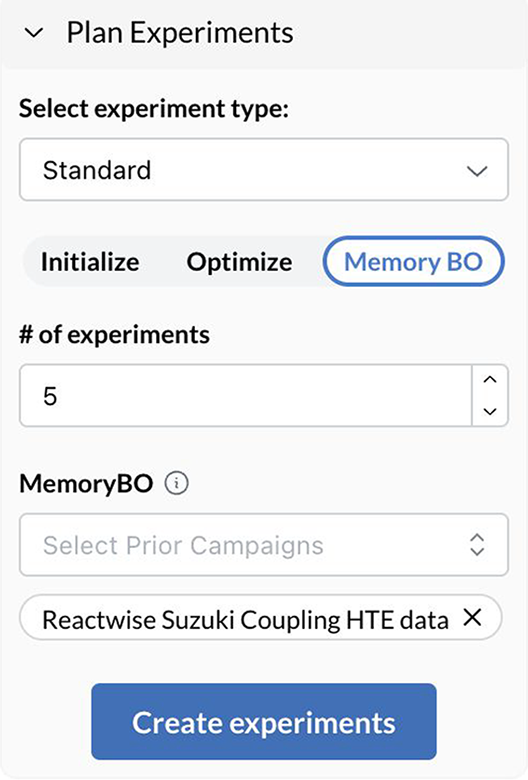
• Upload prior data of similar/related experiments.
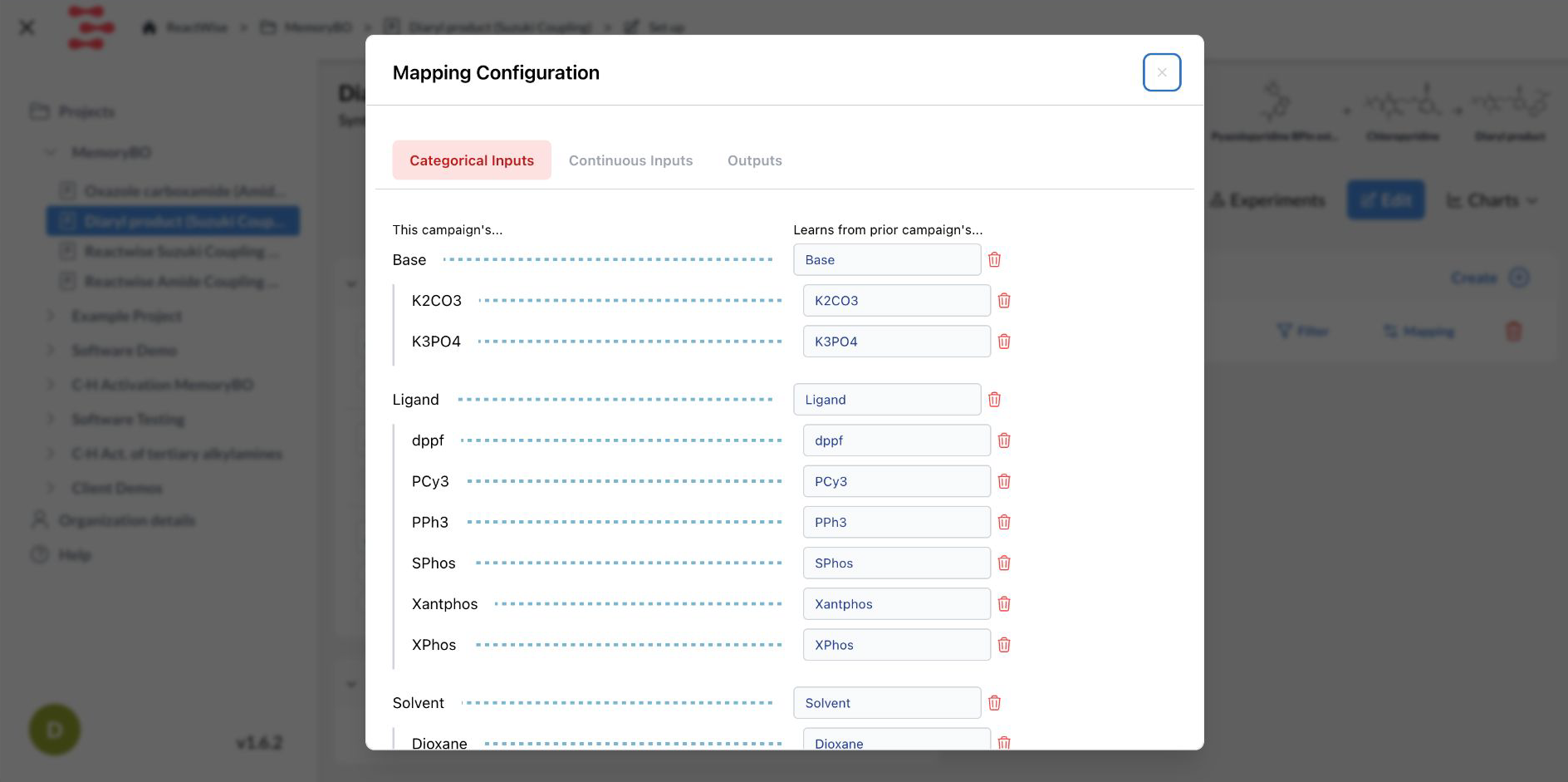
• Map the prior data to your target task.
• Receive intelligent predictions from the start.
Sample Processing
Filter Substrate Scope
Execute