
What’s faster than Bayesian Optimization?
What’s faster than Bayesian Optimization?
Bayesian Optimization with memory.
Finding ideal reaction conditions remains one of the slowest, most tedious bottlenecks in chemical R&D - even for common transformations like amide coupling.
To tackle this, ReactWise has generated a proprietary dataset from thousands of HTE experiments on amide coupling reactions - systematically varying coupling agents, bases, and solvents.
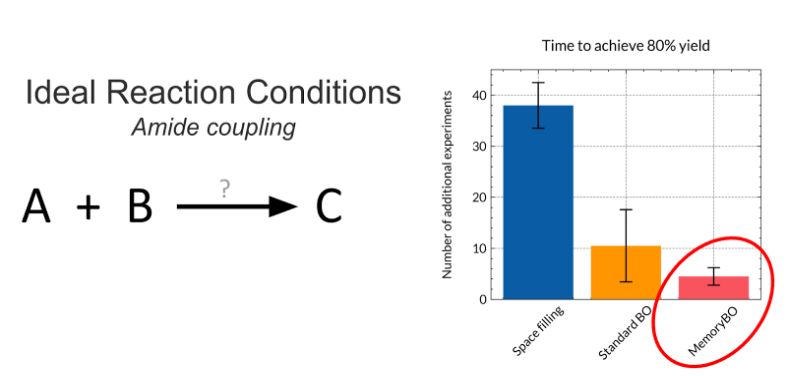
We benchmarked three strategies for optimizing reaction conditions:
- Space-filling design
- Standard Bayesian Optimization
- MemoryBO, our transfer learning BO algorithm.
As shown above, MemoryBO consistently outperforms Standard BO, achieving target yields (≥80%) in far fewer experiments.
How?
MemoryBO pre-trains a probabilistic surrogate model on structured, domain-specific HTE data. When faced with a new optimization task, it initializes the search with this prior - effectively "remembering" what has worked in similar chemical contexts. This allows it to avoid low-value experiments and converge much faster.
This changes the game.
With MemoryBO, we’re no longer optimizing from scratch. We’re standing on the shoulders of data.
At ReactWise, we’re actively expanding our library of pre-trained models across the most frequently used transformations in pharma, including Amide couplings, Buchwald-Hartwig couplings, and Suzuki couplings, enabling faster, smarter optimization for real-world chemistry.
We’re currently conducting ML research to ensure robustness and generalizability across substrate classes, and we can’t wait to make these models available to clients worldwide.
If you want to learn more - or are working on similar reactions - get in touch. We're always keen to talk about data.

