
Why we built our own open-source data cleaning pipeline for chemical reaction data
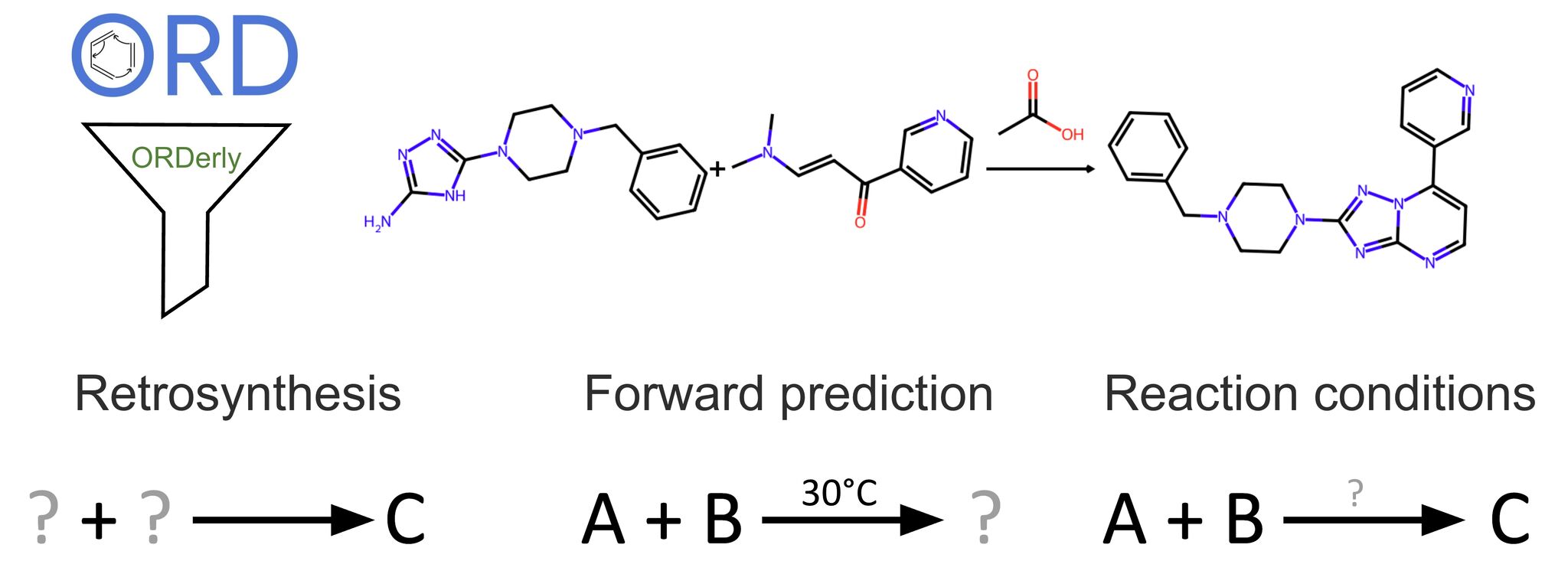
There is currently no clean, usable dataset to test our algorithm modelling chemical reactions and predicting reaction conditions. That is why we built ORDerly.
ORDerly is a structured, open-source repository for cleaning chemical reaction data from the Open Reaction Database. It’s designed for machine learning from day one - standardized SMILES, curated reagents, harmonized conditions. No more weeks wasted cleaning up raw files.
And recently, due to a community request, we open-sourced the transformer models (based on Schwaller el al.'s Molecular Transformer) we trained on ORDerly data.
Trained from scratch, the transformer models handle retrosynthesis, forward predictions, and condition predictions. The adapted training code is included in the ORDerly repository.
If you're looking for the next research project, how about exploring how well a transformer model trained from scratch on ORDerly data with $200 of compute compares to state-of-the-art general purpose LLMs on these same tasks. I can't imagine it would be a close race.
What do you think?
At ReactWise, we’re committed to open science - not just because it’s the right thing to do, but because collaboration drives better research and better products.
We’re actively working with universities around the world, and many of our best ideas started in a lab notebook - not a pitch deck.
AI for chemistry needs clean data, strong models, and real-world feedback.
That’s the loop we’re trying to close.
Let’s make open science a default, not an exception.

